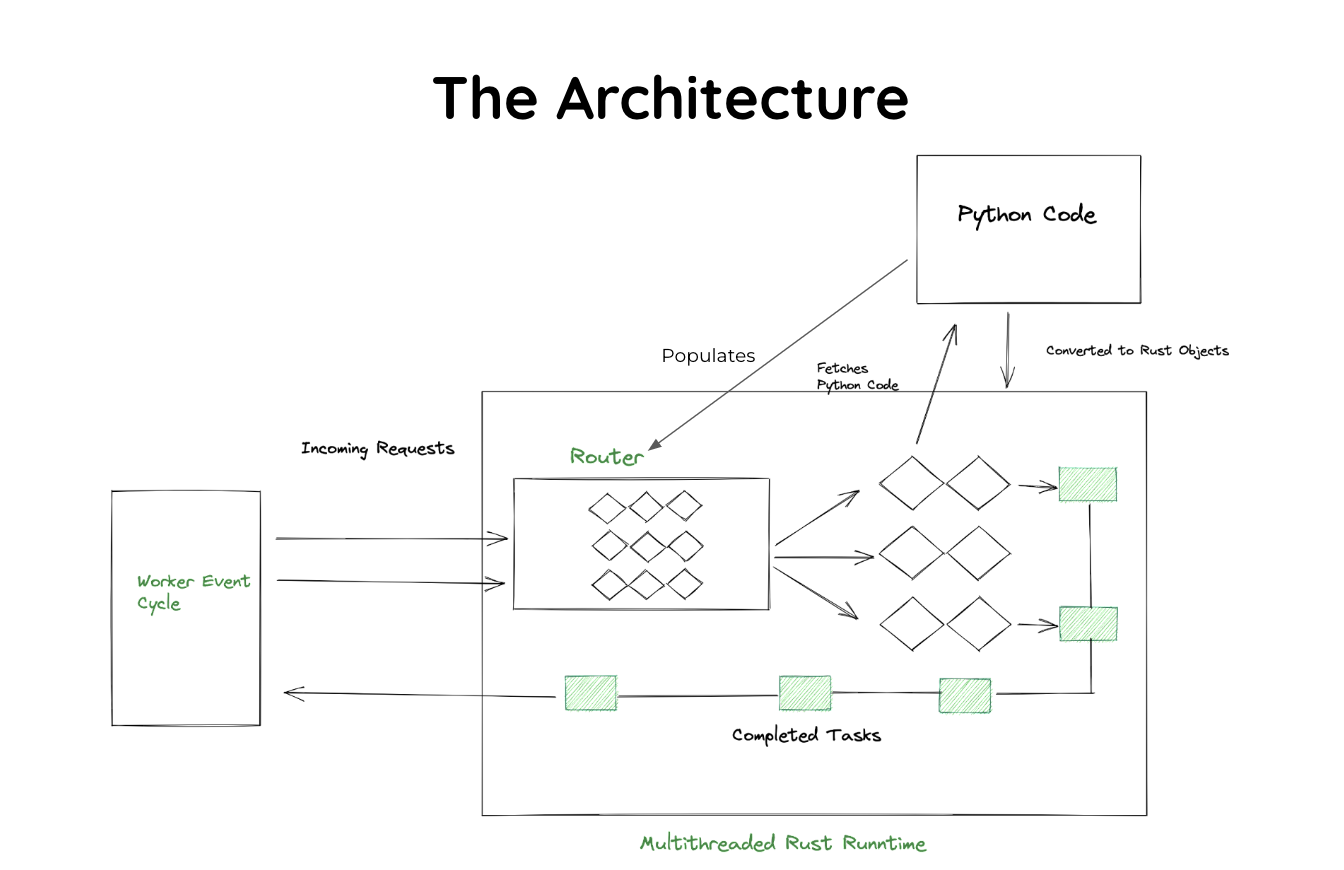
Robyn Architecture Overview
Robyn's unique architecture combines Python's ease of development with Rust's performance. This hybrid design allows developers to write familiar Python code while benefiting from Rust's speed and memory safety.
The Python-Rust Hybrid Design
Two-Layer Architecture
Robyn operates on two interconnected but distinct layers:
Python Layer (Developer Interface):
- Route definitions and decorators (
@app.get,@app.post, etc.) - Request parameter injection and validation
- Business logic execution
- Middleware configuration
- Response formatting
Rust Layer (Performance Engine):
- HTTP request parsing and validation
- URL routing and pattern matching
- WebSocket connection management
- Static file serving
- Response serialization
- Memory management
Communication Bridge
The layers communicate through PyO3, a Rust crate that enables seamless Python-Rust interoperability:
- Function Registration: Python route handlers are registered with the Rust runtime at startup
- Request Flow: Rust handles incoming HTTP requests and calls Python handlers via PyO3
- Response Processing: Python responses are converted back to Rust for efficient HTTP serialization
Why This Design Works
- Best of Both Worlds: Python's productivity with Rust's performance
- Zero-Copy Operations: Minimal data copying between layers
- Memory Safety: Rust prevents common server vulnerabilities
- Async Integration: Seamless integration with Python's asyncio
Server Process Model
Robyn is built on a multi-process, multi-threaded model that maximizes hardware utilization:
Master Process
The master process in Robyn is responsible for initializing the server, managing worker processes, and handling signals. It creates a socket and passes it to the worker processes, allowing them to accept connections. The master process is implemented in Python, providing a familiar interface for developers while leveraging Rust's performance for core operations.
216:257:robyn/__init__.py
def start(self, host: str = "127.0.0.1", port: int = 8080, _check_port: bool = True):
"""
Starts the server
:param host str: represents the host at which the server is listening
:param port int: represents the port number at which the server is listening
:param _check_port bool: represents if the port should be checked if it is already in use
"""
host = os.getenv("ROBYN_HOST", host)
port = int(os.getenv("ROBYN_PORT", port))
open_browser = bool(os.getenv("ROBYN_BROWSER_OPEN", self.config.open_browser))
if _check_port:
while self.is_port_in_use(port):
logger.error("Port %s is already in use. Please use a different port.", port)
try:
port = int(input("Enter a different port: "))
except Exception:
logger.error("Invalid port number. Please enter a valid port number.")
continue
logger.info("Robyn version: %s", __version__)
logger.info("Starting server at http://%s:%s", host, port)
mp.allow_connection_pickling()
run_processes(
host,
port,
self.directories,
self.request_headers,
self.router.get_routes(),
self.middleware_router.get_global_middlewares(),
self.middleware_router.get_route_middlewares(),
self.web_socket_router.get_routes(),
self.event_handlers,
self.config.workers,
self.config.processes,
self.response_headers,
open_browser,
)
Worker Processes
Robyn uses multiple worker processes to handle incoming requests. Each worker process is capable of managing multiple threads, allowing for efficient concurrent processing. The number of worker processes can be configured using the --processes flag, with a default of 1.
66:116:robyn/processpool.py
def init_processpool(
directories: List[Directory],
request_headers: Headers,
routes: List[Route],
global_middlewares: List[GlobalMiddleware],
route_middlewares: List[RouteMiddleware],
web_sockets: Dict[str, WebSocket],
event_handlers: Dict[Events, FunctionInfo],
socket: SocketHeld,
workers: int,
processes: int,
response_headers: Headers,
) -> List[Process]:
process_pool = []
if sys.platform.startswith("win32") or processes == 1:
spawn_process(
directories,
request_headers,
routes,
global_middlewares,
route_middlewares,
web_sockets,
event_handlers,
socket,
workers,
response_headers,
)
return process_pool
for _ in range(processes):
copied_socket = socket.try_clone()
process = Process(
target=spawn_process,
args=(
directories,
request_headers,
routes,
global_middlewares,
route_middlewares,
web_sockets,
event_handlers,
copied_socket,
workers,
response_headers,
),
)
process.start()
process_pool.append(process)
return process_pool
Worker Threads
Within each worker process, Robyn utilizes multiple threads to handle requests concurrently. The number of worker threads can be configured using the --workers flag. By default, Robyn uses a single worker thread per process.
Request Processing Flow
Understanding how requests flow through Robyn's hybrid architecture:
1. Request Arrival
HTTP Request → Rust HTTP Parser → Fast Validation
2. Routing and Matching
Validated Request → Rust Router (matchit crate) → Route Resolution
3. Parameter Extraction
Matched Route → Rust Parameter Parser → Path/Query/Header Extraction
4. Python Handler Execution
Extracted Parameters → PyO3 Bridge → Python Handler → Response
5. Response Processing
Python Response → Rust Serializer → HTTP Response → Client
Rust Integration Deep Dive
Robyn's Rust integration is powered by the Tokio async runtime and several high-performance crates:
Core Components
- Tokio Runtime: Handles async I/O and task scheduling
- Actix Web: Provides HTTP server functionality
- PyO3: Enables Python-Rust communication
- matchit: Ultra-fast URL routing with radix tree implementation
- Serde: JSON serialization/deserialization
Performance Benefits
- Zero-allocation routing using compiled radix trees
- Memory-efficient HTTP parsing with minimal allocations
- Async task scheduling without GIL interference
- Direct memory access for static file serving
76:107:src/server.rs
pub fn start(
&mut self,
py: Python,
socket: &PyCell<SocketHeld>,
workers: usize,
) -> PyResult<()> {
pyo3_log::init();
if STARTED
.compare_exchange(false, true, SeqCst, Relaxed)
.is_err()
{
debug!("Robyn is already running...");
return Ok(());
}
let raw_socket = socket.try_borrow_mut()?.get_socket();
let router = self.router.clone();
let const_router = self.const_router.clone();
let middleware_router = self.middleware_router.clone();
let web_socket_router = self.websocket_router.clone();
let global_request_headers = self.global_request_headers.clone();
let global_response_headers = self.global_response_headers.clone();
let directories = self.directories.clone();
let asyncio = py.import("asyncio")?;
let event_loop = asyncio.call_method0("new_event_loop")?;
asyncio.call_method1("set_event_loop", (event_loop,))?;
let startup_handler = self.startup_handler.clone();
let shutdown_handler = self.shutdown_handler.clone();
Const Requests Optimization
Robyn's "Const Requests" feature provides significant performance improvements for static endpoints:
How Const Requests Work
- Route Registration: Routes marked with
const=Trueare identified at startup - Response Caching: The first response is cached in Rust memory
- Direct Serving: Subsequent requests bypass Python entirely
- Zero Overhead: Responses are served directly from Rust with minimal CPU usage
Performance Impact
- 10x faster response times compared to regular Python handlers
- Minimal memory usage with efficient caching
- No Python GIL contention for cached responses
- Ideal for: Health checks, API metadata, configuration endpoints
Example Usage
from robyn import Robyn
app = Robyn(__file__)
# Regular route - executes Python on every request
@app.get("/dynamic")
def dynamic_endpoint():
return {"timestamp": time.time()} # Changes every request
# Const route - cached in Rust after first request
@app.get("/health", const=True)
def health_check():
return {"status": "healthy", "version": "1.0.0"} # Static response
# Perfect for API metadata
@app.get("/api/info", const=True)
def api_info():
return {
"name": "My API",
"version": "2.1.0",
"endpoints": ["/users", "/posts", "/health"]
}
When to Use Const Routes
- Health/status endpoints that return consistent data
- API documentation or metadata endpoints
- Configuration endpoints with static values
- Version information endpoints
Scaling Configuration Guide
Understanding Processes vs Workers
Processes:
- Independent Python interpreters
- Share no memory (shared-nothing architecture)
- Each process has its own GIL
- Best for CPU-bound applications
- Recommended: 1 process per CPU core
Workers (within each process):
- Threads sharing the same Python interpreter
- Affected by Python's GIL
- Better for I/O-bound operations
- Recommended: 2-4 workers per process
Configuration Strategies
CPU-Intensive Applications
# Favor more processes, fewer workers
python app.py --processes=8 --workers=1
# Example: Image processing, data analysis, calculations
I/O-Intensive Applications
# Favor fewer processes, more workers
python app.py --processes=2 --workers=8
# Example: Database queries, API calls, file operations
Balanced Applications
# General-purpose configuration
python app.py --processes=4 --workers=2
# Most web applications fit this pattern
Hardware-Based Recommendations
For a system with N CPU cores:
| Application Type | Processes | Workers | Total Concurrency |
|---|---|---|---|
| CPU-bound | N | 1 | N |
| I/O-bound | N/2 | 4 | 2N |
| Balanced | N/2 | 2 | N |
| High-traffic | N | 2 | 2N |
Performance Testing
Always benchmark your specific application:
# Test different configurations
python app.py --processes=1 --workers=1 # Baseline
python app.py --processes=2 --workers=2 # Moderate scaling
python app.py --processes=4 --workers=1 # CPU-focused
python app.py --processes=2 --workers=4 # I/O-focused
python app.py --fast # Auto-optimized
Scaling Considerations
- Robyn's multi-process model allows it to scale across multiple CPU cores effectively.
- The combination of Python and Rust allows for both ease of development and high performance.
- Const Requests feature can significantly improve performance for routes with constant output.
- When scaling, consider both the number of processes and workers to find the optimal configuration for your hardware and application needs.
Development Mode
Robyn provides a development mode that can be activated using the --dev flag. This mode is designed for ease of development and includes features like hot reloading. Note that in development mode, multi-process and multi-worker configurations are disabled to ensure consistent behavior during development.
92:101:robyn/argument_parser.py
if self.dev and (self.processes != 1 or self.workers != 1):
raise Exception("--processes and --workers shouldn't be used with --dev")
if self.dev and args.log_level is None:
self.log_level = "DEBUG"
elif args.log_level is None:
self.log_level = "INFO"
else:
self.log_level = args.log_level
By understanding these design principles and adjusting the configuration accordingly, developers can leverage Robyn's unique architecture to build high-performance web applications that efficiently utilize system resources.
Design Diagram